0.10823 probability of running into word X).
Just goes to show the deep roots between Numbers and Letters!
Anyways, so I was pretty psyched, so I figured to do some Mathematicking and constructed a graph and module to compare the differences between the expected frequency of a word and the actual frequency of a word in various corpora of the ages.

First, I'll go over the
code!:
1) Find a plain text or html file of the whole corpus (must be large) to be tested. I used Aeschylus' The Eumenides and Stevenson's Treasure Island. I found them via OTA, the Oxford Text Archive.
2)
Import into Mathematica the whole file.
3) Separate each word so they're individual elements of one list, using
StringSeparate.
4)
Tally the list, SortBy the Last element, then finally Reverse it to get the most frequent word on top of the list rather than at bottom, just to satiate your burning desires of which word is most frequent. I'll allow you to figure what word would be most common.
We want to make a
ListPlot of the differences in probability of running into any word, as a function of its popularity ranking. Luckily, Mathematica's ListPlot will automatically number each entry in a uni-level list so we can just worry about getting the probabilities for both Zipf's expected values and the Author's actual values.
5) Form two empty lists,
expectedValList and actualValListListPlot.
Make a
Module which takes one parameter rank_.
The
Module will Append the Zipf's expected probability, calculated by:
where
to the
expectedValList and we Append the actual probability of running into the word:
where
to the
actualValList.
DATA:
6) Now run a
While loop for however many top words you want to compare Zipf's expectations to, and...
PLOT:
7) Now it's a matter of
ListPlot!
RESULTS:
A comparison of Stevenson's frequency of word choice (red) and Zipf's expected frequency of word choice (blue). This is for Treasure Island.
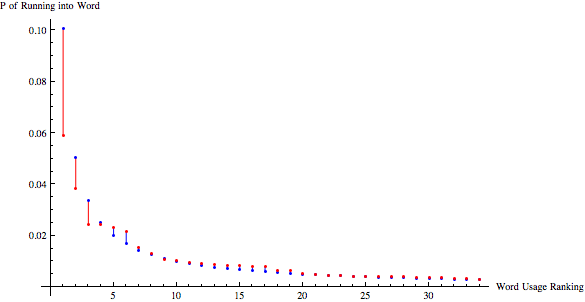 Words in Rank:
Words in Rank: {the, and, a, of, I, to, was, in, had, he, that, his, with, my, as, you, for, on, it, at, we, but, not, were, me, by, have, all, said, be, this, one, from, so, out}
Similar graph for Aeschylus' The Eumenides:

Words in Rank:
{the, to, of, a, in, and, I, you, my, your, this, for, with, all, his, on, CHORUS, our, who, that, LEADER, no, from, is, by, will, he, as, You, not, we, those, their, ATHENA, have}
UNCERTAINTIES:
There are quite a few discrepancies in the Aeschylus Zipf comparison, compared to Stevenson Zipf comparison. I'm assuming this is because it was translated from Greek, and thus not applicable to English, even though written in English syntax. Also, the code I've written does not account for discrepancies in punctuation, so the counts may be off, but I wouldn't believe it to significantly affect the count. The discrepancies get noticeably less with each ranking increase, percentage-wise.
